
When discussing monitoring, the focus is often only on how we detect things that have failed and how quickly we can find them, but this is a small part of monitoring and is worthy of expansion.
Monitoring for failure
Colleagues and customers usually tell us if things are broken, but it’s nice to get ahead and fix or mitigate the problem before they can say anything.
To monitor for failure, we decide what failure looks like, choose how often we’re going to check for failure, how many failures are not tolerable and what action we’re going to perform when we see a failure.
Monitoring for performance
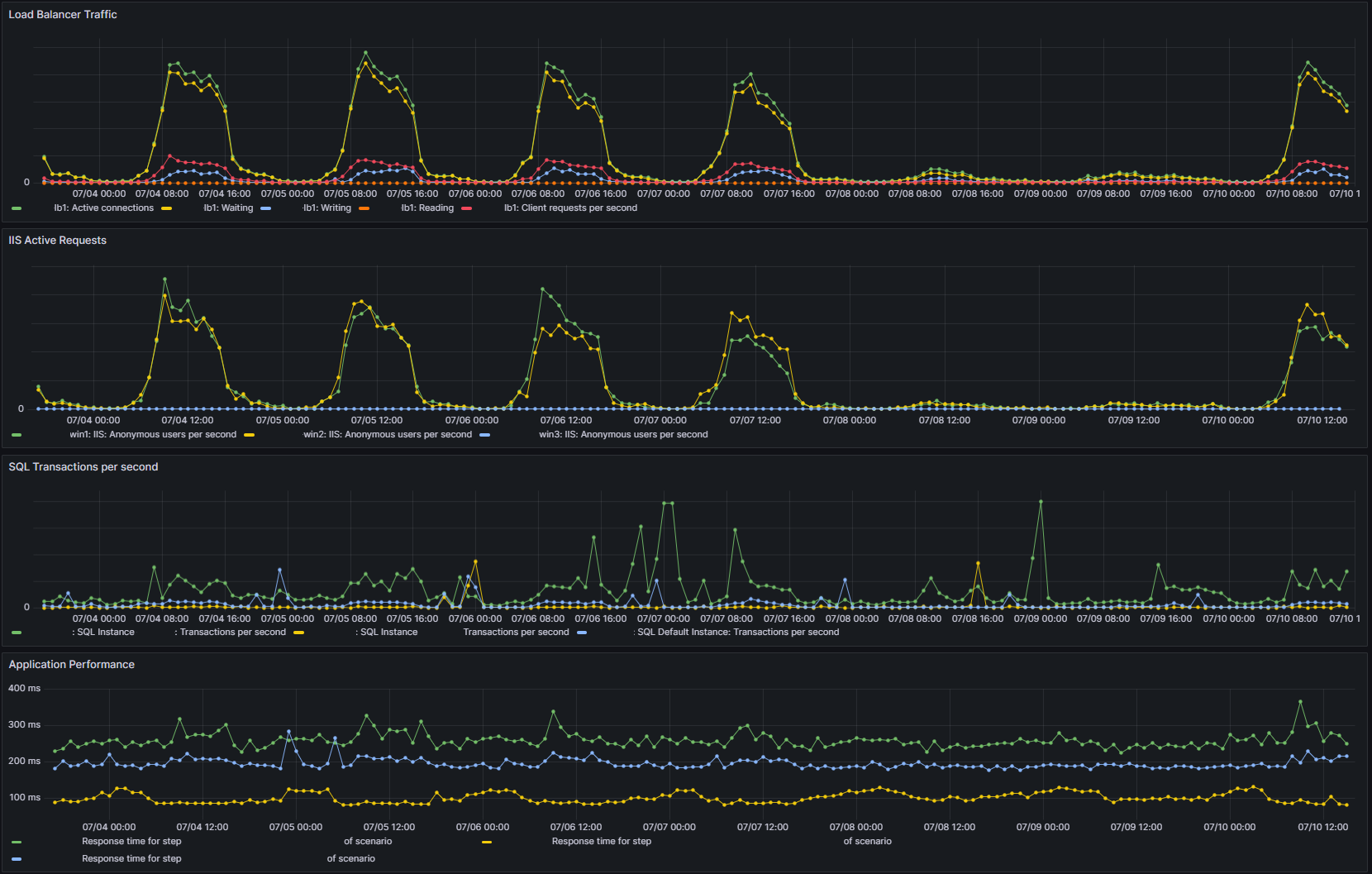 While monitoring for failure, we should gather valuable performance information (remembering failure to perform sufficiently is usually also a failure).
While monitoring for failure, we should gather valuable performance information (remembering failure to perform sufficiently is usually also a failure).
Performance monitoring is sometimes an afterthought, but we frequently see failure prediction manifested as sub-standard performance in advance.
Monitoring for capacity
In addition to failure and performance, we should monitor for capacity; many failures and sub-standard performance can be avoided with appropriate capacity monitoring and planning.
Capacity not only includes things like disk space and bandwidth but also things like auto-scaling limits, inode usage, CPU steal time and failover overhead (capacity of hardware to absorb failure of other hardware).
Monitoring for configuration and state
There are many methods to monitor for changes to the configuration of an application or system. Still, it’s often helpful to watch configurations (files or states) in the same system as availability and performance so that any changes can be notified and, when necessary, more easily correlated or used to suppress the alerting of other issues.
Monitoring for trends
One of the most overlooked monitoring elements is the long-term trend data it produced.
Comparing the performance, capacity or state of a system when everything was happy yesterday can help identify what has caused things to be unhappy today from the changes and results.
Long-term trends can help identify if the problem has been developing and only recently met the failure threshold (being slower than a particular SLA or failing more than n times in the t period).
Keep updated with the latest from Pipe Ten by subscribing below.
Monitoring for monitoring
You’d be surprised how often we’ve seen SLA breached, not because there is a lack of monitoring but because nobody thought to monitor that the monitoring continued to work correctly.
If a monitoring system sends an email when a 0 value returned becomes a 1, will it send an email if doesn’t see either a 0 or a 1 for a period of time?
Monitoring for SLA and compliance
ISO27001 and other similar standards will typically result in a set of company objectives linked to the availability or performance of your web services. Historic monitoring and reporting of these can be necessary for identify areas for continual improvement and otherwise provide reporting for periodic management review.
Monitoring for sanity
A risk that is monitored is a risk that is controlled, and your sub-conscious is going to appreciate knowing that if you have a small problem, you might know about it before it becomes a big problem or when you have a big problem, you can quickly recognise it’s a big problem and appropriately resource the incident. We all sleep a little easier at night knowing failures will happen, and we’re in an excellent position to learn about and deal with them.
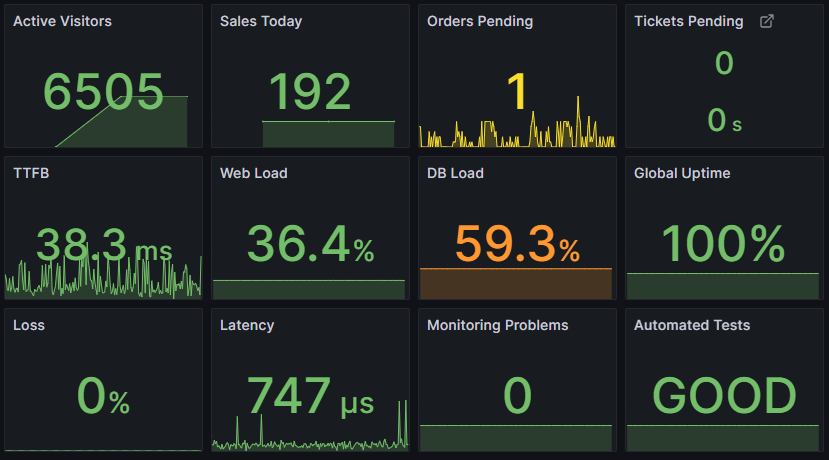
Monitoring for success
The goal of everything we do at Pipe Ten is to enable your web success; avoiding or identifying failures is just one of the many areas we can help.
There’s no particular one-size-fits-all when it comes to general monitoring tools, but we have a vast amount of experience deploying monitoring for customers based on the following:
We also provide other less general monitoring tools with focus on availability, performance, security, vulnerability and compliance.
Did we miss a reason we monitor generally beyond failure? Can we help you sleep easier? Let us know!
Author: Carl Heaton
Carl is a founder of Pipe Ten and uses his role as Technical Director to drive the company’s vision to transform business online in delivering it’s mission to forge agile technical partnerships that accelerate web success. Carl boasts an illustrious career spanning over two decades, starting as a fledgling web developer in his teens, he swiftly ascended the ranks, honing his skills in architecting secure web application infrastructure. With his finger on the pulse of emerging web technologies, Carl has tracked and influenced the ever changing world of cyber security, internet governance, industry regulations and information security compliance ensuring Pipe Ten successfully achieved and maintain ISO/IEC 27001 certification.